DeepSeek представила передові ШІ-моделі V3.2 та V3.2-Speciale

За даними DeepSeek, нові відкриті моделі V3.2 та V3.2-Speciale здатні конкурувати, а місцями і перевершувати найпотужніші сучасні ШІ-системи, включаючи GPT-5 від OpenAI та Gemini 3 Pro від Google.
Замість того, щоб гнатися за масштабом за будь-яку ціну, DeepSeek продовжує дотримуватися стратегії, заснованої на ефективності. Поки американські лабораторії покладаються на великі кластери нових чипів, DeepSeek стверджує, що її відточений підхід до навчання дозволяє досягти порівнянного рівня інтелекту на більш доступному устаткуванні. За словами компанії, навіть стандартна модель спочатку підтримує інструментальне та структуроване міркування — користувачеві не потрібно переходити в окремий режим reasoning.
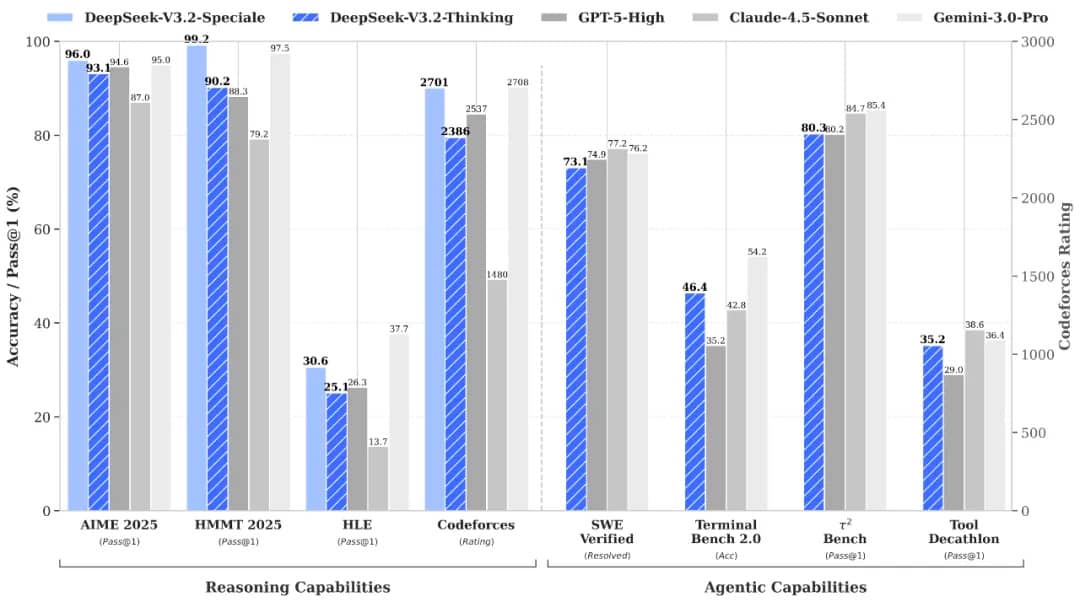
Головну увагу привертає версія V3.2-Speciale. DeepSeek заявляє, що ця модель перевершила GPT-5 у внутрішніх тестах і показує результати рівня Gemini 3 Pro у завданнях, які потребують глибоких міркувань. На підтвердження компанія наводить свої виступи на Міжнародній математичній олімпіаді та Міжнародній олімпіаді з інформатики 2025 року, наголосивши, що остаточні рішення доступні для ознайомлення.
За словами DeepSeek, такий стрибок став можливим завдяки двом ключовим інноваціям: власному механізму розрідженої уваги, оптимізованому для роботи з довгим контекстом, і розширеному конвеєру навчання з підкріпленням, що включає більше 85 000 складних багатокрокових завдань, створених за допомогою внутрішньої системи «agentic ta».
Тим, хто хоче випробувати новинки, модель V3.2 вже доступна на сайті DeepSeek, у мобільних додатках та через API. Більше експериментальна V3.2-Speciale працює тільки через тимчасову API-точку, яка буде відключена після 15 грудня 2025 року. Зараз вона функціонує як двигун, розрахований виключно на міркування, без підтримки виклику інструментів.
Джерело: gizmochina
AI

Компанія 1Password офіційно оголосила про запуск інтеграції з платформою штучного інтелекту Claude від Anthropic. Нова функція дає змогу ШІ використовувати збережені в менеджері паролів облікові дані для виконання дій у браузері, при цьому самі паролі залишаються недоступними як для Claude, так і для серверів Anthropic.

Apple розглядає можливість придбання однієї або кількох компаній, що спеціалізуються на створенні серверних процесорів і прискорювачів для штучного інтелекту. Така угода може стати однією з найбільших технологічних покупок в історії виробника iPhone та допомогти йому прискорити розвиток власної інфраструктури для Apple Intelligence і нової Siri.

OpenAI офіційно дебютувала на ринку апаратного забезпечення, але її перший пристрій виявився зовсім не таким, як очікували багато хто. Замість компактного ШІ-гаджета без екрана, про який останніми тижнями активно повідомляли інсайдери, компанія анонсувала Codex Micro — програмовану механічну клавіатуру, створену для розробників, які працюють із платформою Codex.

Samsung Electronics вирішила суттєво прискорити реалізацію одного з найбільших проєктів у своїй історії. На тлі стрімкого зростання попиту на чипи для систем штучного інтелекту компанія планує запустити перший завод у новому напівпровідниковому комплексі в Йоніні на два роки раніше, ніж передбачалося спочатку.